

ارسال شده توسط: امیرعباس کریمی 29 شهریور 1404 ساعت 17:48
پژوهشی جدید نشان میدهد چتجیپیتی در خلاصهنویسی مقالات علمی، دقت را فدای سادگی میکند و نمیتوان به آن اعتماد کامل داشت.
خلاصهسازی یافتههای پیچیده علمی برای مخاطبان غیرمتخصص، یکی از وظایف مهم خبرنگاران حوزه علم است. مدلهای زبانی بزرگ (LLM) نیز همواره بهعنوان ابزاری قدرتمند برای این کار معرفی شدهاند؛ اما مطالعهای یکساله توسط انجمن پیشرفت علم آمریکا (AAAS) نشان میدهد که واقعیت با این تصور فاصله زیادی دارد. نتایج این پژوهش، تردیدهای جدی را درباره قابلیتهای فعلی این ابزارها در تولید محتوای علمی دقیق مطرح میکند.
نتایج یک تحقیق یک ساله چه چیزی را نشان میدهد؟
تیم «SciPak» در AAAS که به طور معمول برای نشریه Science و خدماتی مانند EurekAlert خلاصههای خبری تولید میکند، تصمیم گرفت عملکرد چتجیپیتی (ChatGPT)را در این زمینه ارزیابی کند. این خلاصهها برای انتقال اطلاعات حیاتی مانند فرضیه، روشها و بستر مطالعات به سایر خبرنگاران طراحی شدهاند. طی دسامبر ۲۰۲۳ تا دسامبر ۲۰۲۴، محققان AAAS هفتهای تا دو مقاله را برای خلاصهنویسی به چتجیپیتی سپردند و از سه پرامپت با سطح جزئیات متفاوت استفاده کردند. تمرکز اصلی بر مقالاتی با اصطلاحات تخصصی، یافتههای بحثبرانگیز یا فرمتهای غیرمتعارف بود. در این تحقیق از نسخه «پلاس» مدلهای GPT-4 و GPT-4o استفاده شد.
در مجموع ۶۴ خلاصه تولید شد که توسط همان نویسندگان SciPak که قبلاً مقالات اصلی را خلاصه کرده بودند، ارزیابی شدند. ارزیابیها هم کمی و هم کیفی بودند. نتایج نشان داد که چتجیپیتی میتواند ساختار یک خلاصه به سبک SciPak را تا حد قابل قبولی شبیهسازی کند، اما نثری تولید میکند که دقت را فدای سادگی میکند و نیازمند راستیآزمایی دقیق توسط نویسندگان SciPak است. نویسنده AAAS، ابیگیل آیزنشتات، اظهار داشت که این فناوریها در این مرحله برای تیم SciPak، هنوز برای استفاده در مرحله اصلی آماده نیستند.
بیشتر بخوانید
- کاربران از ChatGPT برای چه کاری استفاده میکنند؟ OpenAI با بررسی 1.5 میلیون چت پاسخ را یافت
- سومین شکایت حقوقی علیه هوش مصنوعی: آیا چتبات Character AI عامل خودکشی نوجوانان است؟
- هکرهای کره شمالی با استفاده از ChatGPT به جنگ ارتش کره جنوبی رفتند!
- اوپنایآی از GPT-5-Codex، ابزار جدید هوش مصنوعی برای توسعهدهندگان رونمایی کرد
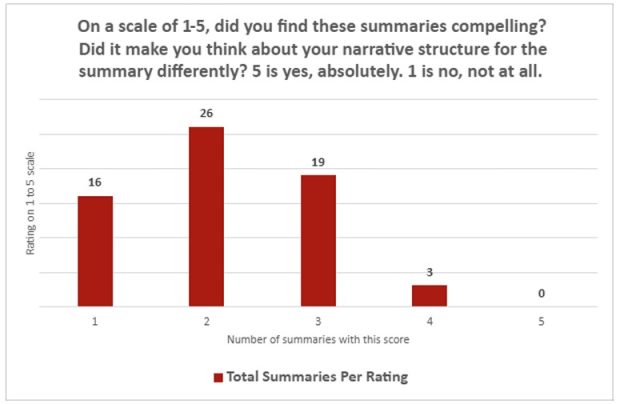
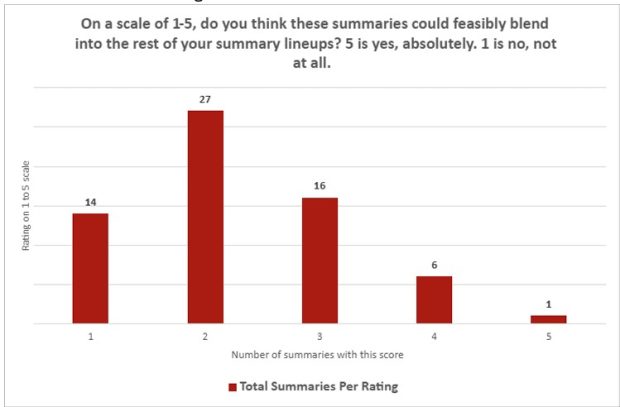
در نظرسنجیهای کمی، نتایج بهشدت یکطرفه بودند. در پاسخ به اینکه آیا خلاصههای تولید شده توسط چتجیپیتی میتوانند «بهراحتی در کنار سایر خلاصههای شما قرار بگیرند»، میانگین امتیاز تنها ۲٫۲۶ از ۵ بود (که ۱ به معنای «اصلاً نه» و ۵ به معنای «کاملاً بله» است). در مورد جذابیت خلاصهها، میانگین امتیاز ۲٫۱۴ بود. در مجموع، تنها یک خلاصه در هر دو سوال امتیاز ۵ گرفت، در حالی که ۳۰ خلاصه امتیاز ۱ دریافت کردند.
چرا دقت فدای سادگی میشود؟
نویسندگان در ارزیابیهای کیفی خود، شکایات متعددی را مطرح کردند. آنها به این نکته اشاره کردند که چتجیپیتی اغلب همبستگی (Correlation) و علیت (Causation) را با هم اشتباه میگیرد، قادر به ارائه بستر مناسب (مانند کند بودن عملگرهای نرم) نیست و تمایل دارد نتایج را با کلماتی مانند «پیشگامانه» و «جدید» بیش از حد بزرگنمایی کند (البته این مورد آخر با اصلاح پرامپتها کاهش یافت).
محققان دریافتند که مدلهای زبانی بزرگ (Large Language Models) معمولاً در رونویسی محتوای مقاله علمی، بهویژه در مقالات بدون ظرافتهای زیاد، خوب عمل میکنند. اما چتجیپیتی در ترجمه این یافتهها، یعنی پرداختن به روششناسی، محدودیتها یا پیامدهای کلی، ضعیف بود. این نقاط ضعف بهویژه در مقالاتی که نتایج متفاوت یا چندگانه داشتند یا زمانی که از LLM خواسته میشد دو مقاله مرتبط را در یک خلاصه ترکیب کند، بیشتر خود را نشان دادند.

چالشها و چشمانداز آینده
با وجود اینکه لحن و سبک خلاصههای چتجیپیتی اغلب با محتوای انسانی مطابقت داشت، «نگرانیها در مورد صحت واقعی محتوای تولید شده توسط LLM» بسیار رایج بود. به گفته خبرنگاران، حتی استفاده از خلاصههای چتجیپیتی بهعنوان «نقطه شروع» برای ویرایش انسانی نیز «همانند نگارش خلاصهها از صفر، یا حتی بیشتر، تلاش نیاز دارد»؛ چرا که نیاز به «راستیآزمایی گسترده» وجود دارد.
این نتایج شاید با توجه به مطالعات قبلی که نشان میدهند موتورهای جستجوی هوش مصنوعی تا ۶۰ درصد اوقات به منابع خبری نادرست استناد میکنند، چندان غافلگیرکننده نباشند. با این حال، نقاط ضعف خاص این ابزار در مورد مقالات علمی که دقت و وضوح ارتباط در آنها حیاتی است، اهمیت بیشتری پیدا میکند. در نهایت، خبرنگاران AAAS به این نتیجه رسیدند که چتجیپیتی «استانداردهای تیم SciPak را برای خلاصهنویسی برآورده نمیکند». البته آنها اشاره کردند که در صورت «بهروزرسانی عمده» چتجیپیتی، ممکن است ارزش تکرار این آزمایش را داشته باشد. مدل GPT-5 در ماه اوت به صورت عمومی معرفی شد و احتمالاً در آینده نزدیک مورد بررسی قرار خواهد گرفت.


ارسال نظر شما
مجموع نظرات : 0 در انتظار بررسی : 0 انتشار یافته : 0